Self-supervised Learning¶
This bolts module houses a collection of all self-supervised learning models.
Self-supervised learning extracts representations of an input by solving a pretext task. In this package, we implement many of the current state-of-the-art self-supervised algorithms.
Self-supervised models are trained with unlabeled datasets
Use cases¶
Here are some use cases for the self-supervised package.
Extracting image features¶
The models in this module are trained unsupervised and thus can capture better image representations (features).
In this example, we’ll load a resnet 18 which was pretrained on imagenet using CPC as the pretext task.
from pl_bolts.models.self_supervised import SimCLR
# load resnet50 pretrained using SimCLR on imagenet
weight_path = 'https://pl-bolts-weights.s3.us-east-2.amazonaws.com/simclr/bolts_simclr_imagenet/simclr_imagenet.ckpt'
simclr = SimCLR.load_from_checkpoint(weight_path, strict=False)
simclr_resnet50 = simclr.encoder
simclr_resnet50.eval()
This means you can now extract image representations that were pretrained via unsupervised learning.
Example:
my_dataset = SomeDataset()
for batch in my_dataset:
x, y = batch
out = simclr_resnet50(x)
Train with unlabeled data¶
These models are perfect for training from scratch when you have a huge set of unlabeled images
from pl_bolts.models.self_supervised import SimCLR
from pl_bolts.models.self_supervised.simclr import SimCLREvalDataTransform, SimCLRTrainDataTransform
train_dataset = MyDataset(transforms=SimCLRTrainDataTransform())
val_dataset = MyDataset(transforms=SimCLREvalDataTransform())
# simclr needs a lot of compute!
model = SimCLR()
trainer = Trainer(tpu_cores=128)
trainer.fit(
model,
DataLoader(train_dataset),
DataLoader(val_dataset),
)
Research¶
Mix and match any part, or subclass to create your own new method
from pl_bolts.models.self_supervised import CPC_v2
from pl_bolts.losses.self_supervised_learning import FeatureMapContrastiveTask
amdim_task = FeatureMapContrastiveTask(comparisons='01, 11, 02', bidirectional=True)
model = CPC_v2(contrastive_task=amdim_task)
Contrastive Learning Models¶
Contrastive self-supervised learning (CSL) is a self-supervised learning approach where we generate representations of instances such that similar instances are near each other and far from dissimilar ones. This is often done by comparing triplets of positive, anchor and negative representations.
In this section, we list Lightning implementations of popular contrastive learning approaches.
AMDIM¶
-
class
pl_bolts.models.self_supervised.AMDIM(datamodule='cifar10', encoder='amdim_encoder', contrastive_task=torch.nn.Module, image_channels=3, image_height=32, encoder_feature_dim=320, embedding_fx_dim=1280, conv_block_depth=10, use_bn=False, tclip=20.0, learning_rate=0.0002, data_dir='', num_classes=10, batch_size=200, num_workers=16, **kwargs)[source] Bases:
pytorch_lightning.PyTorch Lightning implementation of Augmented Multiscale Deep InfoMax (AMDIM).
Paper authors: Philip Bachman, R Devon Hjelm, William Buchwalter.
Model implemented by: William Falcon
This code is adapted to Lightning using the original author repo (the original repo).
Example
>>> from pl_bolts.models.self_supervised import AMDIM ... >>> model = AMDIM(encoder='resnet18')
Train:
trainer = Trainer() trainer.fit(model)
- Parameters
datamodule¶ (
Union[str,LightningDataModule]) – A LightningDatamoduleencoder¶ (
Union[str,Module,LightningModule]) – an encoder string or modelencoder_feature_dim¶ (
int) – Called ndf in the paper, this is the representation size for the encoder.embedding_fx_dim¶ (
int) – Output dim of the embedding function (nrkhs in the paper) (Reproducing Kernel Hilbert Spaces).tclip¶ (
int) – soft clipping non-linearity to the scores after computing the regularization term and before computing the log-softmax. This is the ‘second trick’ used in the paper
BYOL¶
-
class
pl_bolts.models.self_supervised.BYOL(num_classes, learning_rate=0.2, weight_decay=1.5e-06, input_height=32, batch_size=32, num_workers=0, warmup_epochs=10, max_epochs=1000, base_encoder='resnet50', encoder_out_dim=2048, projector_hidden_size=4096, projector_out_dim=256, **kwargs)[source] Bases:
pytorch_lightning.PyTorch Lightning implementation of Bootstrap Your Own Latent (BYOL)
Paper authors: Jean-Bastien Grill, Florian Strub, Florent Altché, Corentin Tallec, Pierre H. Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Daniel Guo, Mohammad Gheshlaghi Azar, Bilal Piot, Koray Kavukcuoglu, Rémi Munos, Michal Valko.
- Model implemented by:
Warning
Work in progress. This implementation is still being verified.
- TODOs:
verify on CIFAR-10
verify on STL-10
pre-train on imagenet
Example:
model = BYOL(num_classes=10) dm = CIFAR10DataModule(num_workers=0) dm.train_transforms = SimCLRTrainDataTransform(32) dm.val_transforms = SimCLREvalDataTransform(32) trainer = pl.Trainer() trainer.fit(model, datamodule=dm)
Train:
trainer = Trainer() trainer.fit(model)
CLI command:
# cifar10 python byol_module.py --gpus 1 # imagenet python byol_module.py --gpus 8 --dataset imagenet2012 --data_dir /path/to/imagenet/ --meta_dir /path/to/folder/with/meta.bin/ --batch_size 32
CPC (V2)¶
PyTorch Lightning implementation of Data-Efficient Image Recognition with Contrastive Predictive Coding
Paper authors: (Olivier J. Hénaff, Aravind Srinivas, Jeffrey De Fauw, Ali Razavi, Carl Doersch, S. M. Ali Eslami, Aaron van den Oord).
Model implemented by:
To Train:
import pytorch_lightning as pl
from pl_bolts.models.self_supervised import CPC_v2
from pl_bolts.datamodules import CIFAR10DataModule
from pl_bolts.models.self_supervised.cpc import (
CPCTrainTransformsCIFAR10, CPCEvalTransformsCIFAR10)
# data
dm = CIFAR10DataModule(num_workers=0)
dm.train_transforms = CPCTrainTransformsCIFAR10()
dm.val_transforms = CPCEvalTransformsCIFAR10()
# model
model = CPC_v2()
# fit
trainer = pl.Trainer()
trainer.fit(model, datamodule=dm)
To finetune:
python cpc_finetuner.py
--ckpt_path path/to/checkpoint.ckpt
--dataset cifar10
--gpus 1
CIFAR-10 and STL-10 baselines¶
CPCv2 does not report baselines on CIFAR-10 and STL-10 datasets. Results in table are reported from the YADIM paper.
Dataset |
test acc |
Encoder |
Optimizer |
Batch |
Epochs |
Hardware |
LR |
|---|---|---|---|---|---|---|---|
CIFAR-10 |
84.52 |
Adam |
64 |
1000 (upto 24 hours) |
1 V100 (32GB) |
4e-5 |
|
STL-10 |
78.36 |
Adam |
144 |
1000 (upto 72 hours) |
4 V100 (32GB) |
1e-4 |
|
ImageNet |
54.82 |
Adam |
3072 |
1000 (upto 21 days) |
64 V100 (32GB) |
4e-5 |
CIFAR-10 pretrained model:
from pl_bolts.models.self_supervised import CPC_v2
weight_path = 'https://pl-bolts-weights.s3.us-east-2.amazonaws.com/cpc/cpc-cifar10-v4-exp3/epoch%3D474.ckpt'
cpc_v2 = CPC_v2.load_from_checkpoint(weight_path, strict=False)
cpc_v2.freeze()
Pre-training:

Fine-tuning:

STL-10 pretrained model:
from pl_bolts.models.self_supervised import CPC_v2
weight_path = 'https://pl-bolts-weights.s3.us-east-2.amazonaws.com/cpc/cpc-stl10-v0-exp3/epoch%3D624.ckpt'
cpc_v2 = CPC_v2.load_from_checkpoint(weight_path, strict=False)
cpc_v2.freeze()
Pre-training:

Fine-tuning:

CPC (v2) API¶
-
class
pl_bolts.models.self_supervised.CPC_v2(encoder_name='cpc_encoder', patch_size=8, patch_overlap=4, online_ft=True, task='cpc', num_workers=4, num_classes=10, learning_rate=0.0001, pretrained=None, **kwargs)[source] Bases:
pytorch_lightning.- Parameters
encoder_name¶ (
str) – A string for any of the resnets in torchvision, or the original CPC encoder, or a custon nn.Module encoderpatch_overlap¶ (
int) – How much overlap each patch should haveonline_ft¶ (
bool) – If True, enables a 1024-unit MLP to fine-tune onlinetask¶ (
str) – Which self-supervised task to use (‘cpc’, ‘amdim’, etc…)pretrained¶ (
Optional[str]) – If true, will use the weights pretrained (using CPC) on Imagenet
Moco (v2) API¶
-
class
pl_bolts.models.self_supervised.Moco_v2(base_encoder='resnet18', emb_dim=128, num_negatives=65536, encoder_momentum=0.999, softmax_temperature=0.07, learning_rate=0.03, momentum=0.9, weight_decay=0.0001, data_dir='./', batch_size=256, use_mlp=False, num_workers=8, *args, **kwargs)[source] Bases:
pytorch_lightning.PyTorch Lightning implementation of Moco
Paper authors: Xinlei Chen, Haoqi Fan, Ross Girshick, Kaiming He.
Code adapted from facebookresearch/moco to Lightning by:
- Example::
from pl_bolts.models.self_supervised import Moco_v2 model = Moco_v2() trainer = Trainer() trainer.fit(model)
CLI command:
# cifar10 python moco2_module.py --gpus 1 # imagenet python moco2_module.py --gpus 8 --dataset imagenet2012 --data_dir /path/to/imagenet/ --meta_dir /path/to/folder/with/meta.bin/ --batch_size 32
- Parameters
base_encoder¶ (
Union[str,Module]) – torchvision model name or torch.nn.Modulenum_negatives¶ (
int) – queue size; number of negative keys (default: 65536)encoder_momentum¶ (
float) – moco momentum of updating key encoder (default: 0.999)softmax_temperature¶ (
float) – softmax temperature (default: 0.07)datamodule¶ – the DataModule (train, val, test dataloaders)
-
forward(img_q, img_k)[source] - Input:
im_q: a batch of query images im_k: a batch of key images
- Output:
logits, targets
-
init_encoders(base_encoder)[source] Override to add your own encoders
SimCLR¶
PyTorch Lightning implementation of SimCLR
Paper authors: Ting Chen, Simon Kornblith, Mohammad Norouzi, Geoffrey Hinton.
Model implemented by:
To Train:
import pytorch_lightning as pl
from pl_bolts.models.self_supervised import SimCLR
from pl_bolts.datamodules import CIFAR10DataModule
from pl_bolts.models.self_supervised.simclr.transforms import (
SimCLREvalDataTransform, SimCLRTrainDataTransform)
# data
dm = CIFAR10DataModule(num_workers=0)
dm.train_transforms = SimCLRTrainDataTransform(32)
dm.val_transforms = SimCLREvalDataTransform(32)
# model
model = SimCLR(num_samples=dm.num_samples, batch_size=dm.batch_size, dataset='cifar10')
# fit
trainer = pl.Trainer()
trainer.fit(model, datamodule=dm)
CIFAR-10 baseline¶
Implementation |
test acc |
Encoder |
Optimizer |
Batch |
Epochs |
Hardware |
LR |
|---|---|---|---|---|---|---|---|
resnet50 |
LARS |
2048 |
800 |
TPUs |
1.0/1.5 |
||
Ours |
88.50 |
LARS |
2048 |
800 (4 hours) |
8 V100 (16GB) |
1.5 |
CIFAR-10 pretrained model:
from pl_bolts.models.self_supervised import SimCLR
weight_path = 'https://pl-bolts-weights.s3.us-east-2.amazonaws.com/simclr/bolts_simclr_imagenet/simclr_imagenet.ckpt'
simclr = SimCLR.load_from_checkpoint(weight_path, strict=False)
simclr.freeze()
Pre-training:

Fine-tuning (Single layer MLP, 1024 hidden units):

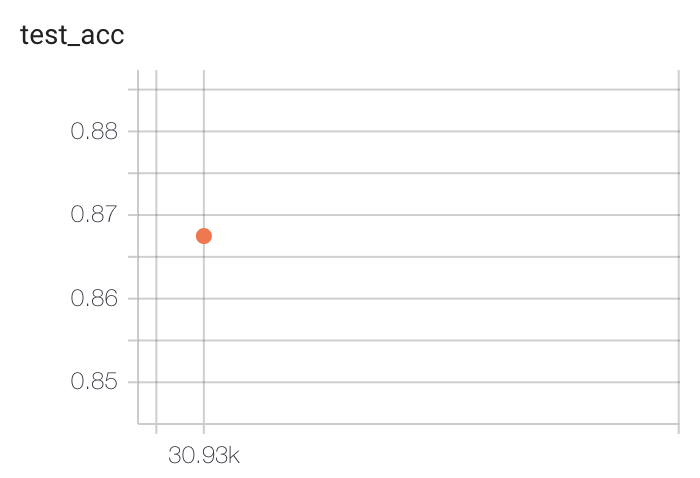
To reproduce:
# pretrain
python simclr_module.py
--gpus 8
--dataset cifar10
--batch_size 256
-- num_workers 16
--optimizer sgd
--learning_rate 1.5
--exclude_bn_bias
--max_epochs 800
--online_ft
# finetune
python simclr_finetuner.py
--gpus 4
--ckpt_path path/to/simclr/ckpt
--dataset cifar10
--batch_size 64
--num_workers 8
--learning_rate 0.3
--num_epochs 100
Imagenet baseline for SimCLR¶
Implementation |
test acc |
Encoder |
Optimizer |
Batch |
Epochs |
Hardware |
LR |
|---|---|---|---|---|---|---|---|
resnet50 |
LARS |
4096 |
800 |
TPUs |
4.8 |
||
Ours |
68.4 |
LARS |
4096 |
800 |
64 V100 (16GB) |
4.8 |
Imagenet pretrained model:
from pl_bolts.models.self_supervised import SimCLR
weight_path = 'https://pl-bolts-weights.s3.us-east-2.amazonaws.com/simclr/bolts_simclr_imagenet/simclr_imagenet.ckpt'
simclr = SimCLR.load_from_checkpoint(weight_path, strict=False)
simclr.freeze()
To reproduce:
# pretrain
python simclr_module.py
--dataset imagenet
--data_path path/to/imagenet
# finetune
python simclr_finetuner.py
--gpus 8
--ckpt_path path/to/simclr/ckpt
--dataset imagenet
--data_dir path/to/imagenet/dataset
--batch_size 256
--num_workers 16
--learning_rate 0.8
--nesterov True
--num_epochs 90
SimCLR API¶
-
class
pl_bolts.models.self_supervised.SimCLR(gpus, num_samples, batch_size, dataset, num_nodes=1, arch='resnet50', hidden_mlp=2048, feat_dim=128, warmup_epochs=10, max_epochs=100, temperature=0.1, first_conv=True, maxpool1=True, optimizer='adam', exclude_bn_bias=False, start_lr=0.0, learning_rate=0.001, final_lr=0.0, weight_decay=1e-06, **kwargs)[source] Bases:
pytorch_lightning.- Parameters
-
nt_xent_loss(out_1, out_2, temperature, eps=1e-06)[source] assume out_1 and out_2 are normalized out_1: [batch_size, dim] out_2: [batch_size, dim]
SwAV¶
PyTorch Lightning implementation of SwAV Adapted from the official implementation
Paper authors: Mathilde Caron, Ishan Misra, Julien Mairal, Priya Goyal, Piotr Bojanowski, Armand Joulin.
Implementation adapted by:
To Train:
import pytorch_lightning as pl
from pl_bolts.models.self_supervised import SwAV
from pl_bolts.datamodules import STL10DataModule
from pl_bolts.models.self_supervised.swav.transforms import (
SwAVTrainDataTransform, SwAVEvalDataTransform
)
from pl_bolts.transforms.dataset_normalizations import stl10_normalization
# data
batch_size = 128
dm = STL10DataModule(data_dir='.', batch_size=batch_size)
dm.train_dataloader = dm.train_dataloader_mixed
dm.val_dataloader = dm.val_dataloader_mixed
dm.train_transforms = SwAVTrainDataTransform(
normalize=stl10_normalization()
)
dm.val_transforms = SwAVEvalDataTransform(
normalize=stl10_normalization()
)
# model
model = SwAV(
gpus=1,
num_samples=dm.num_unlabeled_samples,
dataset='stl10',
batch_size=batch_size
)
# fit
trainer = pl.Trainer(precision=16)
trainer.fit(model)
Pre-trained ImageNet¶
We have included an option to directly load ImageNet weights provided by FAIR into bolts.
You can load the pretrained model using:
ImageNet pretrained model:
from pl_bolts.models.self_supervised import SwAV
weight_path = 'https://pl-bolts-weights.s3.us-east-2.amazonaws.com/swav/swav_imagenet/swav_imagenet.pth.tar'
swav = SwAV.load_from_checkpoint(weight_path, strict=True)
swav.freeze()
STL-10 baseline¶
The original paper does not provide baselines on STL10.
Implementation |
test acc |
Encoder |
Optimizer |
Batch |
Queue used |
Epochs |
Hardware |
LR |
|---|---|---|---|---|---|---|---|---|
Ours |
SwAV resnet50 |
LARS |
128 |
No |
100 (~9 hr) |
1 V100 (16GB) |
1e-3 |
STL-10 pretrained model:
from pl_bolts.models.self_supervised import SwAV
weight_path = 'https://pl-bolts-weights.s3.us-east-2.amazonaws.com/swav/checkpoints/swav_stl10.pth.tar'
swav = SwAV.load_from_checkpoint(weight_path, strict=False)
swav.freeze()
Pre-training:
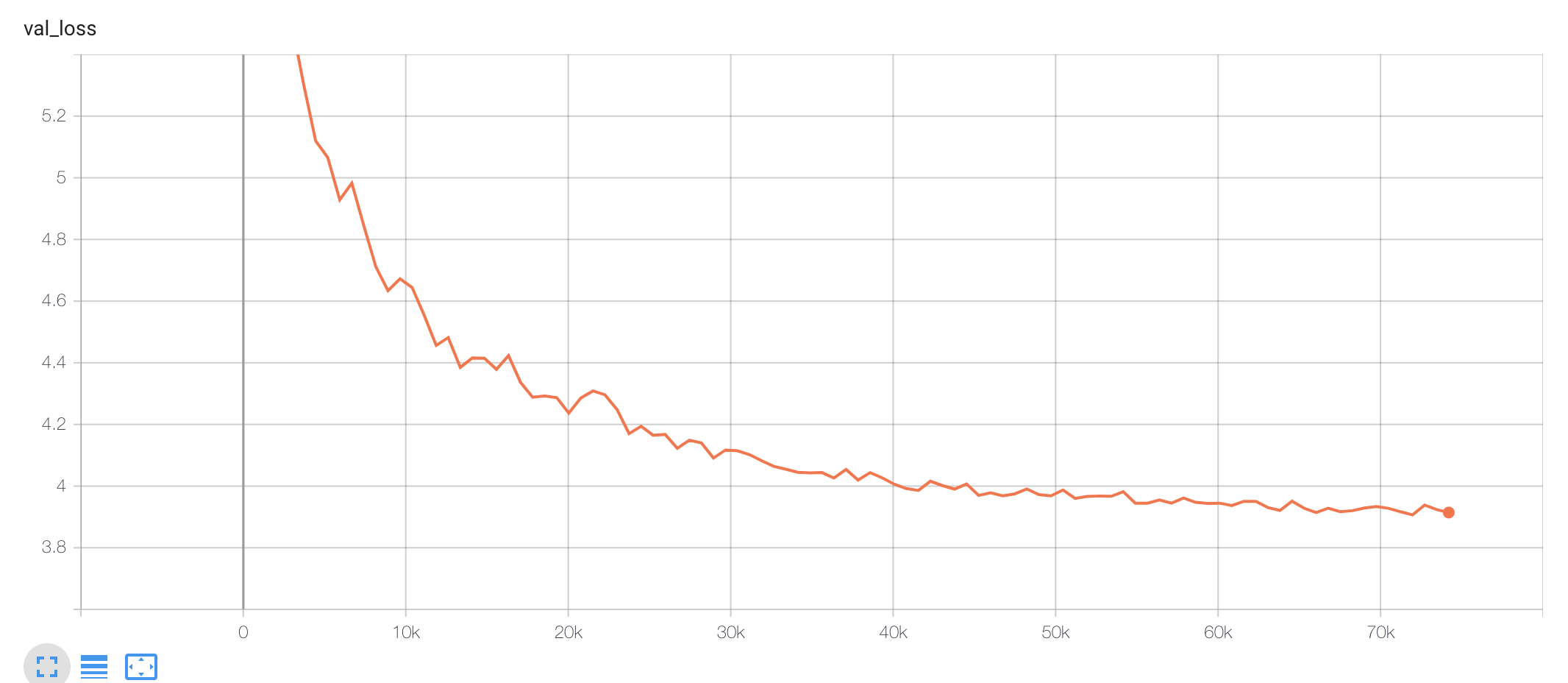

Fine-tuning (Single layer MLP, 1024 hidden units):


To reproduce:
# pretrain
python swav_module.py
--online_ft
--gpus 1
--batch_size 128
--learning_rate 1e-3
--gaussian_blur
--queue_length 0
--jitter_strength 1.
--nmb_prototypes 512
# finetune
python swav_finetuner.py
--gpus 8
--ckpt_path path/to/simclr/ckpt
--dataset imagenet
--data_dir path/to/imagenet/dataset
--batch_size 256
--num_workers 16
--learning_rate 0.8
--nesterov True
--num_epochs 90
Imagenet baseline for SwAV¶
Implementation |
test acc |
Encoder |
Optimizer |
Batch |
Epochs |
Hardware |
LR |
|---|---|---|---|---|---|---|---|
Original |
75.3 |
resnet50 |
LARS |
4096 |
800 |
64 V100s |
4.8 |
Ours |
74 |
LARS |
4096 |
800 |
64 V100 (16GB) |
4.8 |
Imagenet pretrained model:
from pl_bolts.models.self_supervised import SwAV
weight_path = 'https://pl-bolts-weights.s3.us-east-2.amazonaws.com/swav/bolts_swav_imagenet/swav_imagenet.ckpt'
swav = SwAV.load_from_checkpoint(weight_path, strict=False)
swav.freeze()
SwAV API¶
-
class
pl_bolts.models.self_supervised.SwAV(gpus, num_samples, batch_size, dataset, num_nodes=1, arch='resnet50', hidden_mlp=2048, feat_dim=128, warmup_epochs=10, max_epochs=100, nmb_prototypes=3000, freeze_prototypes_epochs=1, temperature=0.1, sinkhorn_iterations=3, queue_length=0, queue_path='queue', epoch_queue_starts=15, crops_for_assign=[0, 1], nmb_crops=[2, 6], first_conv=True, maxpool1=True, optimizer='adam', exclude_bn_bias=False, start_lr=0.0, learning_rate=0.001, final_lr=0.0, weight_decay=1e-06, epsilon=0.05, **kwargs)[source] Bases:
pytorch_lightning.- Parameters
gpus¶ (
int) – number of gpus per node used in training, passed to SwAV module to manage the queue and select distributed sinkhornnum_samples¶ (
int) – number of image samples used for traininghidden_mlp¶ (
int) – hidden layer of non-linear projection head, set to 0 to use a linear projection headwarmup_epochs¶ (
int) – apply linear warmup for this many epochsfreeze_prototypes_epochs¶ (
int) – epoch till which gradients of prototype layer are frozensinkhorn_iterations¶ (
int) – iterations for sinkhorn normalizationqueue_length¶ (
int) – set queue when batch size is small, must be divisible by total batch-size (i.e. total_gpus * batch_size), set to 0 to remove the queueepoch_queue_starts¶ (
int) – start uing the queue after this epochcrops_for_assign¶ (
list) – list of crop ids for computing assignmentnmb_crops¶ (
list) – number of global and local crops, ex: [2, 6]first_conv¶ (
bool) – keep first conv same as the original resnet architecture, if set to false it is replace by a kernel 3, stride 1 conv (cifar-10)maxpool1¶ (
bool) – keep first maxpool layer same as the original resnet architecture, if set to false, first maxpool is turned off (cifar10, maybe stl10)exclude_bn_bias¶ (
bool) – exclude batchnorm and bias layers from weight decay in optimizersfinal_lr¶ (
float) – float = final learning rate for cosine weight decay
SimSiam¶
-
class
pl_bolts.models.self_supervised.SimSiam(gpus, num_samples, batch_size, dataset, num_nodes=1, arch='resnet50', hidden_mlp=2048, feat_dim=128, warmup_epochs=10, max_epochs=100, temperature=0.1, first_conv=True, maxpool1=True, optimizer='adam', exclude_bn_bias=False, start_lr=0.0, learning_rate=0.001, final_lr=0.0, weight_decay=1e-06, **kwargs)[source] Bases:
pytorch_lightning.PyTorch Lightning implementation of Exploring Simple Siamese Representation Learning (SimSiam)
Paper authors: Xinlei Chen, Kaiming He.
- Model implemented by:
Warning
Work in progress. This implementation is still being verified.
- TODOs:
verify on CIFAR-10
verify on STL-10
pre-train on imagenet
Example:
model = SimSiam() dm = CIFAR10DataModule(num_workers=0) dm.train_transforms = SimCLRTrainDataTransform(32) dm.val_transforms = SimCLREvalDataTransform(32) trainer = pl.Trainer() trainer.fit(model, datamodule=dm)
Train:
trainer = Trainer() trainer.fit(model)
CLI command:
# cifar10 python simsiam_module.py --gpus 1 # imagenet python simsiam_module.py --gpus 8 --dataset imagenet2012 --data_dir /path/to/imagenet/ --meta_dir /path/to/folder/with/meta.bin/ --batch_size 32
